Types: Ensuring Smooth Pipelines
We’ve explored how functional programming builds computations using pipelines and expressions, treating functions as first-class values. Now, let’s introduce another crucial concept that ensures these pipelines work reliably: Types.
The Pipeline Requirement: Matching Inputs and Outputs
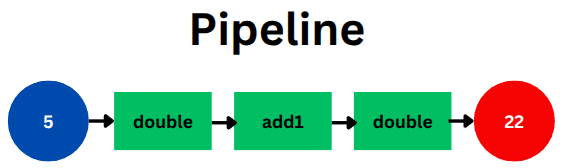
Section titled “The Pipeline Requirement: Matching Inputs and Outputs”Recall our pipeline example:

let double x = x * 2let add1 x = x + 1
let result = 5 // Input is an integer |> double // double must accept an integer // returns an integer (10) |> add1 // add1 must accept an integer // returns an integer (11) |> double // double must accept an integer // returns an integer (22)For data to flow smoothly through this pipeline without errors, a fundamental requirement must be met: **the output of one function must be compatible with the input of the next function.
-
doubletakes a number and produces a number. -
add1must accept the kind of numberdoubleproduced, and it also produces a number. -
The second
doublemust accept the kind of numberadd1produced.
This concept of “what kind of data” a function accepts or returns is formalized by Types.
What are Types?
Section titled “What are Types?”A Type is essentially a classification of data. It tells the compiler and the programmer what kind of value a variable can hold or what kind of input a function expects and output it produces.
Common examples include:
-
int: Integer numbers (e.g.,5,22) -
string: Text data (e.g.,"Hello") -
bool: Boolean values (true,false) -
int -> int: A function that takes anintas input and returns anintas output (like ourdoubleandadd1functions). -
'a -> 'a: A generic function that takes a value of any type'aand returns a value of that same type (like theidfunction).
Types are essential for program correctness. They prevent errors by ensuring that operations are only performed on compatible data. For instance, you can’t meaningfully apply the double function (which expects an int) to the string "hello". The type system catches such mistakes, often before you even run the program.
In the context of our pipeline, types ensure the “pipes fit together” – the output type of double (int) fits the input type of add1 (int), and the output type of add1 (int) fits the input type of the next double (int).
Type Inference: The Compiler’s Superpower
Section titled “Type Inference: The Compiler’s Superpower”Knowing the types of functions is crucial for building correct pipelines. So, how do we know the type of double is int -> int?
In many statically-typed languages (like Java or C++), you often have to explicitly declare the types of functions and variables. However, languages like F# and Haskell feature powerful Type Inference.
Type Inference is the ability of the compiler to automatically deduce the types of expressions, variables, and functions based on how they are used, without requiring explicit type annotations from the programmer.
-
When the F# compiler sees
let double x = x * 2, it knows that the(*)operator typically works onints by default, so it infers thatxmust be anintand the function returns anint. Thus,doubleis inferred to have the typeint -> int. -
Similarly,
add1is inferred asint -> int. -
For
let result = 5 |> double |> add1 |> double, the compiler knows5isint,doublereturnsint,add1returnsint, and the finaldoublereturnsint, so it infers thatresultmust be anint.
The Role of IDEs (like VSCode):
This powerful type inference becomes incredibly helpful when combined with modern IDEs.
let double x = x * 2let add1 x = x + 1
let result = 5 |> double |> add1 |> doubleVSCode IDE Screenshot
Section titled “VSCode IDE Screenshot”
The IDE leverages the compiler’s inference ability to automatically display the inferred types directly in your code.
Even without explicit type annotations, the IDE (using the compiler’s information) shows you the inferred types for double , add1 , and the final result . This helps you understand the data flowing through your pipelines and catches type errors instantly. This automatic, reliable type information provided by the compiler and visualized by the IDE is arguably a cornerstone of productive functional programming – it ensures the pipeline connections are sound.
Contrast with Manual Typing (e.g., TypeScript)
Section titled “Contrast with Manual Typing (e.g., TypeScript)”For example, in TypeScript, while the compiler does perform some local inference, programmers often need to provide explicit type annotations for function arguments and return types to achieve full type safety, especially for complex scenarios.

// Manual type annotation often needed in TypeScripttype DoubleFunc = (a: number) => number;let double: DoubleFunc = a => a * 2;This level of powerful, whole-program type inference is characteristic of languages in the ML family (like F#, OCaml, Haskell) but is less common elsewhere.
While AI tools can assist significantly with TypeScript typing nowadays, it still often involves more manual effort and relies on the programmer’s understanding (or the AI’s potentially non-deterministic suggestion). An incorrect manual annotation can lead to runtime errors or misleading code. The rigorous inference by compilers like F#‘s provides a stronger guarantee directly from the code’s structure.
Summary
Section titled “Summary”-
Types classify data and define the expected inputs and outputs of functions.
-
They are crucial for ensuring data flows correctly through pipelines, matching output types to subsequent input types.
-
Type Inference, especially when combined with IDE support (like in F# with VSCode), automatically determines and displays types, providing strong guarantees and developer assistance without requiring extensive manual annotations.
-
This powerful inference is a key feature supporting the functional programming style, contrasting with languages where type specification is often more manual.